1.停止mysql服务
1 | service mysqld stop |
2.使用安全模式启动mysql
1 | mysqld_safe --skip-grant-tables & |
3.使用root用户登陆mysql
1 | mysql -u root |
4.重置密码
1 | >use mysql; |
5.停止mysql
1 | service mysqld stop |
6.重启mysql
1 | service mysqld start |
7.使用新密码登陆mysql
1 | mysql -u root -p |

龙猫,你怎么可以这么懒!!!!!
1.停止mysql服务
1 | service mysqld stop |
2.使用安全模式启动mysql
1 | mysqld_safe --skip-grant-tables & |
3.使用root用户登陆mysql
1 | mysql -u root |
4.重置密码
1 | >use mysql; |
5.停止mysql
1 | service mysqld stop |
6.重启mysql
1 | service mysqld start |
7.使用新密码登陆mysql
1 | mysql -u root -p |
为了实现该接口,你可以写一个类继承javax.servlet.GenericServlet或是javax.servlet.http.HttpServlet,这两个类实现了Servlet接口定义的一些方法。
用户若想用发一个动态web资源(即开发一个Java程序向浏览器输出数据),需要完成以下2个步骤:
编写一个Java类,实现servlet接口
把开发好的Java类部署到web服务器中
该接口定义了初始化Servlet的方法、响应请求、从一个web容器卸载Servlet,这实质是一个对象的生命周期。
Servlet对象创建,会调用init方法来进行初始化
客户端请求会使用service方法来响应
该servlet停止服务,会使用destroy方法销毁,然后jvm进行垃圾回收
除了生命周期方法,此接口提供getServletConfig方法,该方法可以附加一些启动信息来启动servlet。getServletInfo方法,它允许servlet返回有关自身的基本信息,例如作者,版本和 版权
1 | ##运行用户 [用户组] |
在Java中,将不同来源的资源抽象成URL,通过注册不同的handler(URLStreamHandler)来处理不同来源间的资源读取逻辑。而URL中却没有提供一些基本方法来实现自己的抽象结构。因而Spring提出了一套基于
org.springframework.core.io.Resource和org.springframework.core.io.ResourceLoader接口的资源抽象和加载策略。
1 | package org.springframework.core.io; |
本文主要介绍一些Nginx的最基本功能以及简单配置。
首先,Nginx是一个HTTP服务器,可以将服务器上的静态文件(如HTML、图片)通过HTTP协议展现给客户端。
配置:1
2
3
4
5
6server {
listen 80; # 端口号
location / {
root /usr/share/nginx/html; # 静态文件路径
}
}
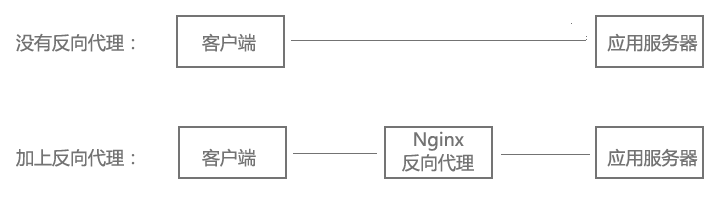
什么是反向代理?
客户端本来可以直接通过HTTP协议访问某网站应用服务器,如果网站管理员在中间加上一个Nginx,客户端请求Nginx,Nginx请求应用服务器,然后将结果返回给客户端,此时Nginx就是反向代理服务器。
配置:1
2
3
4
5
6server {
listen 80;
location / {
proxy_pass http://192.168.20.1:8080; # 应用服务器HTTP地址
}
}
既然服务器可以直接HTTP访问,为什么要在中间加上一个反向代理,不是多此一举吗?反向代理有什么作用?继续往下看,下面的负载均衡、虚拟主机,都基于反向代理实现,当然反向代理的功能也不仅仅是这些。
当网站访问量非常大,网站站长开心赚钱的同时,也摊上事儿了。因为网站越来越慢,一台服务器已经不够用了。于是将相同的应用部署在多台服务器上,将大量用户的请求分配给多台机器处理。同时带来的好处是,其中一台服务器万一挂了,只要还有其他服务器正常运行,就不会影响用户使用。
Nginx可以通过反向代理来实现负载均衡。
配置:1
2
3
4
5
6
7
8
9
10upstream myapp {
server 192.168.20.1:8080; # 应用服务器1
server 192.168.20.2:8080; # 应用服务器2
}
server {
listen 80;
location / {
proxy_pass http://myapp;
}
}
网站访问量大,需要负载均衡。然而并不是所有网站都如此出色,有的网站,由于访问量太小,需要节省成本,将多个网站部署在同一台服务器上。
例如将www.aaa.com和www.bbb.com两个网站部署在同一台服务器上,两个域名解析到同一个IP地址,但是用户通过两个域名却可以打开两个完全不同的网站,互相不影响,就像访问两个服务器一样,所以叫两个虚拟主机。
配置:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19server {
listen 80 default_server;
server_name _;
return 444; # 过滤其他域名的请求,返回444状态码
}
server {
listen 80;
server_name www.aaa.com; # www.aaa.com域名
location / {
proxy_pass http://localhost:8080; # 对应端口号8080
}
}
server {
listen 80;
server_name www.bbb.com; # www.bbb.com域名
location / {
proxy_pass http://localhost:8081; # 对应端口号8081
}
}
在服务器8080和8081分别开了一个应用,客户端通过不同的域名访问,根据server_name可以反向代理到对应的应用服务器。
Spring的核心是IOC和AOP,IOC的本质是将资源文件(如applicationContext.xml)配置的bean(java对象)信息解析出来,然后放到BeanFactory(Spring容器)的Map中(这一步就是所谓的注册),这样以后程序就可以直接从BeanFactory中拿Bean的信息

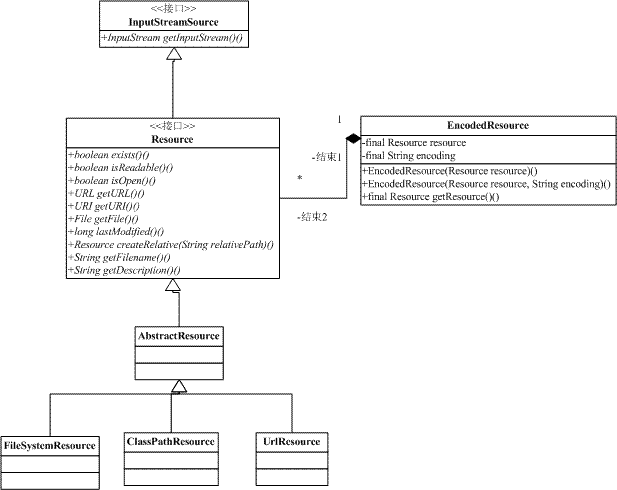
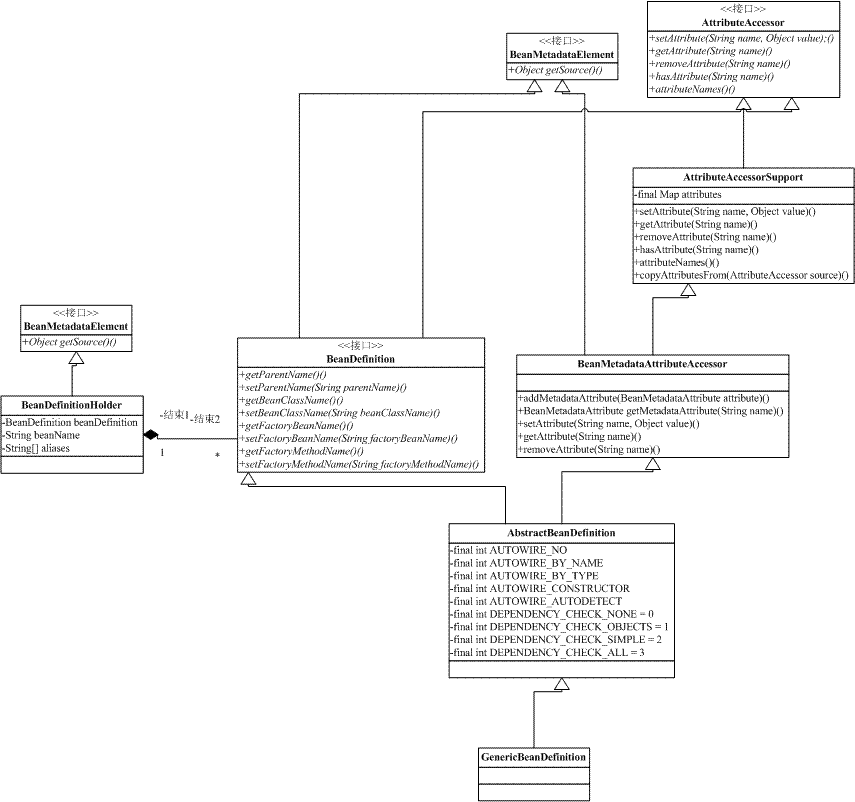
图一:IOC容器主要类图
图二:定义从外面加载资源的接口
图三: bean的相关定义
以上3幅图来源于:链接,感谢^_^
加载配置文件
解析配置文件并注册Bean
实例化Bean
NIO服务端创建过程
打开ServerSocketChannel,用于监听客户端的连接,它是所有客户端连接的父管道
1 | ServerSocketChannel acceptorSrv = ServerSocketChannel.open(); |
绑定监听端口,设置连接为非阻塞模式
1 | acceptorSrv.socket().bind(new InetSocketAddress(InetAddress.getByName("IP"), port)); |
创建Reactor线程,创建多路复用器并启动线程
1 | Selector selector = Selector.open(); |
将ServerSocketChannel注册到Reactor线程的多路复用器Selector上,监听ACCEPT事件
1 | SelectionKey key = acceptorSvr.register(selector, SelectionKey.OP_ACCEPT, ioHandler); |
多路复用器在线程run方法的无限循环体内轮询准备就绪的Key
1 | int num = selector.select(); |
多路复用器监听到有新的客户端接入,处理新的接入请求,完成TCP三次握手,建立物理链路
1 | SocketChannel channel = svrChannel.accept(); |
设置客户端链路的TCP参数
1 | channel.configureBlocking(false); |
将新接入的客户端连接注册到Reactor线程的多路复用器上,监听读操作
1 | SelectionKey key = socketChannel.register(selector, SelectionKey.OP_READ, ioHandler); |
异步读取客户端请求消息到缓冲区
1 | int readNum = channel.read(receiveeBuffer); |
对ByteBuffer进行编解码,如果有半包消息指针Reset,继续读取后续的报文,将解码成功的消息封装成Task,投递到业务线程池中,进行业务逻辑操作
1 |
|
将POJO对象encode成ByteBuffer,调用SocketChannel的异步write接口,将消息异步发送给客服端
1 | socketChannel.write(buffer); |
float和double类型主要是为了科学计算和工程计算而设计的。她们执行二进制浮点运算,这是为了在广泛的数值范围上提供较为精确的快速近似计算而精心设计的。然而,它们并没有提供完全精确的结构,所以不应该被用于需要精确结果的场合。float和double类型尤其不适用于货币计算,因为要让一个float或者double精确地表示0.1(或者10的任何其它负数次方值)是不可能的。
货架上有一排糖果,标价为: 10分、20分、30分、40分、50分、60分…
你要从标价为10分的糖果开始,每种买1颗,一直到不能支付货架上下一种价格的糖果为止。傻子都看得出能买到4种糖果^_^(10+20+30+40),但是编程计算处理不当就会出问题!
1 |
|
运行上面这个程序你会发现你只能买到3中糖果,还剩余0.399999… GG! 出现这种情况的原因是float的计算精度造成的~
1.使用BigDecimal
1 |
|
2.使用int或long
除了使用BigDecimal之外,还有一种方法是使用int或者long,到底使用int或者龙要取决于所涉及数值的大小,同时要自己处理十进制小数点。在这个例子中,最明显的做法是以分为单位进行计算,而不是以元为单位。
1 |
|
对于需要精确答案的计算任务,不要使用float或者double
数值范围没有超过9位十进制数字,就可以使用int,如果不超过18位数字,就可以使用long,如果数值范围可能超过18位数字,就要使用BigDecimal
使用BigDecimal有两个缺点,与使用基本运算类型相比,这样子很不方便,而且很慢。但是计算结果精确,允许你完全控制舍入(8种舍入)